Simple Simulator: T-Shaped vs. I-Shaped Developers

Imagine that you are a manager charged with staffing a new development team. You have important choices to make: What kind of developers do you want? Specialists? Generalists who can do a bit of everything? A mix? Is it worth it to pay more for developers who are a bit more skilled?
Division of Labor vs. T-Shaped People
Most companies I've seen over the years focus on cost. When it comes to developers, that means the default behavior is to get the cheapest ones. That means neither depth of skill, nor range of skills makes much difference. For a developer, having a wide range of skills can even be a detriment, because managers do not know which narrowly defined role to put the developer in.On the other hand, anyone who has even a passing familiarity with Lean, and know a little bit about agile beyond Scrum, has probably come into contact with the concept of T-shaped people.
Most companies develop and organize people according to the Division of Labor principle, the idea that you can increase efficiency by separating tasks into narrow specialities, so that workers can also specialize. This is an important idea. Without it, we would have no industrial revolution, and our world would look very, very different.
The problem is that while the Division of Labour principle works, it can be pushed too far. If the work requires understanding context, if it requires choosing an optimal solution from a wide range of possibilities, if every solution creates new problems...in short, if it is work like software development work, or management, then Division of Labour can cause as many problems it solves.
Nobody can learn to do everything, so we should not, and cannot, abolish the Division of Labour principle altogether. What we often need to do, is to shift the balance a bit.
That is where T-shaped people come in. The idea is simple: Train people in more than one speciality, so that they can work with more than one process step. This allows a team to shift more people to the current bottleneck in a process. It also gives each person a better understanding of the context of their own work, and the consequences of the choices they make.
The Simulator
I recently created a very simple simulator in a spreadsheet to illustrate the effects of narrowing down developer skills too much.In software development, including agile software development, it is very common to have teams of developers divided into two main groups: front-end developers, and back-end developers.
Other teams consist of full-stack developers, individuals who know both front- and back-end development. Of course, being a full-stack developer requires a passion for the work, and also a significant investment in training. Full-stack developers are a good example of T-shaped people: People with a growth mindset, trained to do more than one thing, and usually not afraid to tackle new types of tasks.
Many companies balk at paying for training full-stack developers. The added costs are obvious, but the benefits are a bit more abstract.
The simulator is designed to make the differences between having specialized developers and full-stack developers a bit more visible.
 |
| Simulation: Differences in performance between T-shaped and I-shaped developers |
The picture above shows a run from the simulator. The thick gray line shows the productivity of a team consisting of full-stack developers. The thick yellow line shows the productivity of a team that is identical, except that the developers are divided into front- and back-end developers.
The productivity is measured in stories per sprint, not story-points per sprint. Each story requires both front-end and back-end development.
The two thin dotted lines represent the productivity of the front- and back-end developers. Both team simulations use these numbers to calculate the productivity of the whole team, but they do it a little bit differently:
For the full-stack development team, since all developers can do everything, the numbers are just added together.
For the front/back-end developer team, a story is not finished unless both groups of developers have the capacity to work on it in a sprint. Thus, the total capacity of the team in a sprint, is the lower of the capacities of the two groups, multiplied by two. Thus, if the front-end team can work on four stories, and the back end team can work on three stories, the total capacity is calculated as 3x2=6 stories.
In the initial run, both front- and back-end developer groups can produce 1-10 stories per sprint. The actual capacity is generated by a random number generator. If you have ever measured team productivity, you will know already that in real life, productivity can vary a lot more than this from sprint to sprint.
It is obvious that the full-stack development team is consistently faster than the front/back-end team, but what does that difference mean? Are full-stack developers worth the investment or not?

The simulator calculates the average velocity of the two teams. It also calculates the standard deviation for each velocity graph, and the difference in efficiency between the two average velocities.
Of course, the results will vary from run to run, but I've found that with this initial setup, a difference of about 30% is about normal.
What this means is that if you have to spend 30% more to hire and/or train full-stack developers, it can still be a good investment.
In other words, if it requires one day per week to develop and maintain the skills of full-stack developers, the company is likely to come out ahead financially.
This, of course, is when front- and back-end capacity is, on average, perfectly balanced. What happens if we double the capacity of one of the groups, for example the front-end developers? Well increase the capacity of the full-stack team with the same amount. For example, if the teams had four developers each, we would increase team size to six developers.

Looks like the difference in capacity between the two teams increased. What is going on?
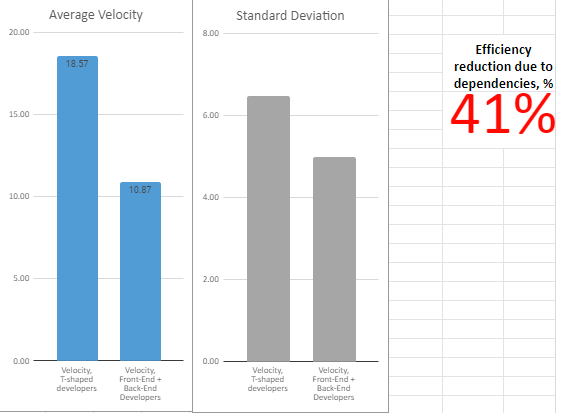
The average velocity of both teams went up, but the velocity of the full-stack team increased more. The difference in efficiency increased, which means the team with front/back-end developers is getting less value per developer.
This makes adding more developers to a team a dicey way to increase productivity, especially since process bottlenecks move around a lot due to the inherent variation in the work. No matter which kind of specialist you add, it will be the wrong kind of specialist a significant portion of the time.
A simple simulation like this is highly useful as an aid to thinking things through, it is by no means a substitute for thinking.
For example, there are an infinite amount of different factors that can affect the productivity of a team. Won't that make the simulation invalid? No.
First, many of those random factors will affect both teams equally. That means the velocity displacement will be equal for both teams, which means the difference in velocity between the teams will remain the same.
Other factors will have quite different effects on the teams. For example, assume that each team has four developers. The front/back-end team has two front-end developers and two back-end developers. If one developer falls ill, the full-stack team has lost 25% of capacity. Thefront/back-end team has lost 50%, because it now has a narrow process bottleneck.
Overall, the full-stack team is a lot more robust. Not accounting for that in the simulation, actually biases the simulation in favor of the front/back-end team.
This means the full-stack team is easily more productive even though the simulation is actually biased against it.
What about the standard deviation bars? Do they have anything significant to add to the story? Yes, but I am saving that for another blog post.



Comments